mPyPl
Monadic Pipeline Library for Python
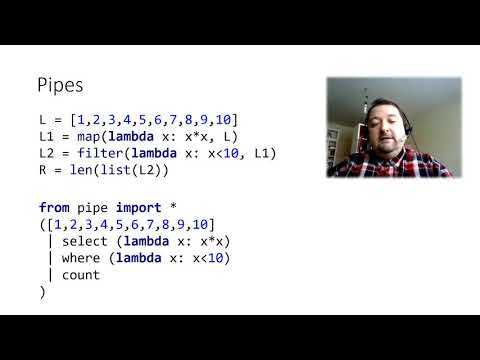
The main goal of mPyPl is to allow data processing tasks in Python to be expressed in a functional way. It uses pipe syntax provided by Pipe package, and augments it with named pipelines.
Often, Pandas is used for many data-processing tasks. The main concept in Pandas is dataframe, which contains data in a tabular form. New features can be computed from the data using computed columns.
In mPyPl, we represent data stream by a generator, which can load data on demand from disk. Data transformations are described by applying lazily-evaluated functions on those data streams. Each data stream typically consists of dictionary-like objects (called mdicts) that contain named fields, and new features can be computed and stored in those fields.
Core Concepts
mPyPl is based on three main ideas:
- using functional programming techniques and lazy pipelines based on Pipe package
- using generators that produce streams of named mdict dictionaries (instead of atomic values), which ‘flow’ through the pipeline
- using a small number of basic operations (the most important one being
apply) that operate on those fields, as well as a number of pre-defined data producers and sinks, hiding the internal implementation complexity
The main advantage of this approach is the ability to create pipelines that combine several streams of data together.
Quickstart
Consider a simple example: we have a number of .jpg files in a directory, and we want to imprint their modification data on top of the image to produce the result similar to photographs with imprinted date produced by some old cameras. This can be accomplished using the following code:
import mPyPl as mp
images = (
mp.get_files('images',ext='.jpg')
| mp.as_field('filename')
| mp.apply('filename','image', lambda x: imread(x))
| mp.apply('filename','date', get_date)
| mp.apply(['image','date'],'result',lambda x: imprint(x[0],x[1]))
| mp.select_field('result')
| mp.as_list)
Let’s go over it line by line:
get_filesis a producer, which returns the generator, giving back all filenames in a givel directory. Generator does not load all files immediatelt, it canyieldnew filename each time it is asked for the next element in a sequence.as_fieldconverts a simple generator into a named stream ofmdicts. We end up having a datastream with named fields, which we can use to compute new named fields.applyis the most important operation, which takes a field (or a bunch of fields), and produces (computes) another field using specified function (typically expressed aslambda). In our case, we first useapplyto load image contents using OpenCV’simread, then to get image date, and finally to do the imprinting.select_fieldgets rid of all fields except the specified one, and leaves just a generator that produces the resultas_listconverts generator to a list that can be used later. Instead, we could also use different sinks here, for example to store images in the output directory, or create a video out of them.
Video Tutorial + Hands On
If you like seeing mPyPl in action - have a look at the tutorial video. You can also follow the same steps using this notebook in Azure - just sign in with Microsoft Account, clone it, and experiment!
You can also watch 3-minute short demo: